Greetings, hacker comrades! Tonight's epistle is gnarly nargery of the best kind. See, we just landed a new virtual machine, compiler, linker, loader, assembler, and debugging infrastructure in Guile, and stories like that don't tell themselves. Oh no. I am a firm believer in Steve Yegge's Big Blog Theory. There are nitties and gritties and they need explication.
a brief brief history
As most of you know, Guile is an implementation of Scheme. It started about 20 years ago as a fork of SCM.
I think this lines-of-code graph pretty much sums up the history:
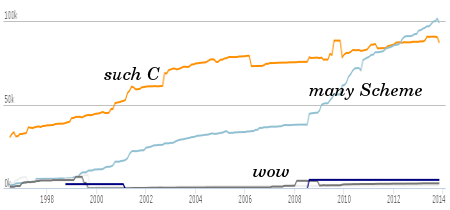
That's from the Ohloh, in case you were wondering. Anyway the story is that in the beginning it was all C, pretty much: Aubrey Jaffer's SCM, just packaged as a library. And it was C people making it, obviously. But Scheme is a beguiling language, and over time Guile has had a way of turning C hackers into Scheme hackers.
I like to think of this graph as showing my ignorance. I started using Guile about 10 years ago, and hacking on it in 2008 or so. In the beginning I was totally convinced by the "C for speed, Scheme for flexibility" thing -- to the extent that I was willing to write off Scheme as inevitably slow. But that's silly of course, and one needs no more proof than the great performance JavaScript implementations have these days.
In 2009, we merged in a bytecode VM and a compiler written in Scheme itself. All that is pretty nifty stuff. We released that version of Guile as 2.0 in 2011, and that's been good times. But it's time to move onward and upward!
A couple of years ago I wrote an article on JavaScriptCore, and in it I spoke longingly of register machines. I think that's probably when I started to make sketches towards Guile 2.2, after having spent time with JavaScriptCore's bytecode compiler and interpreter.
Well, it took a couple of years, but Guile 2.2 is finally a thing. No, we haven't even made any prereleases yet, but the important bits have landed in master. This is the first article about it.
trashing your code
Before I start trashing Guile 2.0, I think it's important to say what it does well. It has a great inlining pass -- better than any mainstream language, I think. Its startup time is pretty good -- around 13 milliseconds on my machine. Its runs faster than other "scripting language" implementations like Python (CPython) or Ruby (MRI). The debugging experience is delightful. You get native POSIX threads. Plus you get all the features of a proper Scheme, like macros and delimited continuations and all of that!
But the Guile 2.0 VM is a stack machine. That means that its instructions usually take their values from the stack, and produce values (if appropriate) by pushing values onto the stack.
The problem with stack machines is that they penalize named values. If I realize that a computation is happening twice and I factor it out to a variable, that means in practice that I allocate a stack frame slot to the value. So far so good. However, to use the value, I have to emit an instruction to fetch the value for use by some other instruction; and to store it, I likewise have to have another instruction to do that.
For example, in Guile 2.0, check out the bytecode produced for this little function:
scheme@(guile-user)> ,disassemble (lambda (x y)
(let ((z (+ x y)))
(* z z)))
0 (assert-nargs-ee/locals 10) ;; 2 args, 1 local
2 (local-ref 0) ;; `x'
4 (local-ref 1) ;; `y'
6 (add)
7 (local-set 2) ;; `z'
9 (local-ref 2) ;; `z'
11 (local-ref 2) ;; `z'
13 (mul)
14 (return)
This is silly. There are seven instructions in the body of this procedure, not counting the prologue and epilogue, and only two of them are needed. The cost of interpreting a bytecode is largely dispatch cost, which is linear in the number of instructions executed, and we see here that we could be some 7/2 = 3.5 times as fast if we could somehow make the operations reference their operands by slot directly.
register vm to the rescue
The solution to this problem is to use a "register machine". I use scare quotes because in fact this is a virtual machine, so unlike a CPU, the number of "registers" is unlimited, and in fact they are just stack slots accessed by index.
So in Guile 2.2, our silly procedure produces the following code:
scheme@(guile-user)> ,disassemble (lambda (x y)
(let ((z (+ x y)))
(* z z)))
0 (assert-nargs-ee/locals 3 1) ;; 2 args, 1 local
1 (add 3 1 2)
2 (mul 3 3 3)
3 (return 3)
This is optimal! There are four things that need to happen, and there are four opcodes that do them. Receiving operands and sending values is essentially free -- they are indexed accesses off of a pointer stored in a hardware register, into memory that is in cache.
This is a silly little example, but especially in loops, Guile 2.2 stomps Guile 2.0. A simple count-up-to-a-billion test runs in 9 seconds on Guile 2.2, compared to 24 seconds in Guile 2.0. Let's make a silly graph!
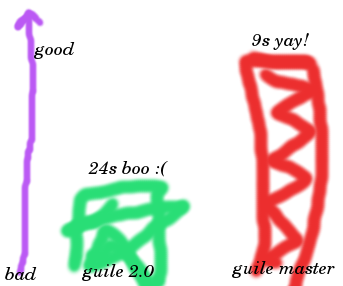
Of course if we compare to V8 for example we find that V8 does a loop-to-a-billion in about 1 second, or 9 times faster. There is some way to go. There are a couple of ways that I could generate better bytecode for this loop, for another 30% speed boost or so, but ultimately we will have to do native compilation. And we will! But that is another post.
gritties
Here's the VM. It's hairy in the prelude, and the whole thing is #included twice in another C file (for a debugging and a non-debugging mode; terrible), but I think it's OK for being in C. (If it were in C++ it could be nicer in various ways.)
The calling convention for this VM is that when a function is called, it receives its arguments on the stack. The stack frame looks like this:
/------------------\ | Local N-1 | <- sp | ... | | Local 1 | | Local 0 | <- fp +==================+ | Return address | | Dynamic link | +==================+ : :
Local 0 holds the procedure being called. Free variables, if any, are stored inline with the (flat) closure. You know how many arguments you get by the difference between the stack pointer (SP) and the frame pointer (FP). There are a number of opcodes to bind optional arguments, keyword arguments, rest arguments, and to skip to other case-lambda clauses.
After deciding that a given clause applies to the actual arguments, a prelude opcode will reset the SP to have enough space to hold all locals. In this way the SP is only manipulated in function prologues and epilogues, and around calls.
Guile's stack is expandable: it is originally only a page or two, and it expands (via mremap if possible) by a factor of two on every overflow, up to a configurable maximum. At expansion you have to rewrite the saved FP chain, but nothing else points in, so it is safe to move the stack.
To call a procedure, you put it and its arguments in contiguous slots, with no live values below them, and two empty slots for the saved instruction pointer (IP) and FP. Getting this right requires some compiler sophistication. Then you reset your SP to hold just the arguments. Then you branch to the procedure's entry, potentially bailing out to a helper if it's not a VM procedure.
To return values, a procedure shuffles the return values down to start from slot 1, resets the stack pointer to point to the last return value, and then restores the saved FP and IP. The calling function knows how many values are returned by looking at the SP. There are convenience instructions for returning and receiving a single value. Multiple values can be returned on the stack easily and efficiently.
Each operation in Guile's VM consists of a number of 32-bit words. The lower 8 bits in the first word indicate the opcode. The width and layout of the operands depends on the word. For example, MOV takes two 12-bit operands. Of course, 4096 locals may not be enough. For that reason there is also LONG-MOV which has two words, and takes two 24-bit operands. In LONG-MOV there are 8 bits of wasted space, but I decided to limit the local frame address space to 24 bits.
In general, most operations cannot address the full 24-bit space. For example, there is ADD, which takes two 8-bit operands and one 8-bit destination. The plan is to have the compiler emit some shuffles in this case, but I haven't hit it yet, and it was too tricky to try to get right in the bootstrapping phase.
JavaScriptCore avoids the address space problem by having all operands be one full pointer wide. This wastes a lot of memory, but they lazily compile and can throw away bytecode and reparse from source as needed, neither of which are true for Guile. We aim to do a good ahead-of-time compilation, to enable self-hosting of the compiler.
JSC's pointer-wide operands do provide the benefit of allowing the "opcode" word to actually hold the address of the label, instead of an index to a table of addresses. This is a great trick, but again it's not applicable to Guile as we don't want to relocate bytecode that we load from disk.
Relative jumps in Guile's VM are 24 bits wide, and are measured in 32-bit units, giving us effectively a 26 bit jump space. Relative references -- references to static data, or other procedures -- are 32 bits wide. I certainly hope that four gigabytes in a compilation unit is enough! By the time it is a problem, hopefully we will be doing native compilation.
Well, those are the basics of Guile's VM. There's more to say, but I already linked to the source, so that should be good enough :) In some future dispatch, we'll talk about the other parts of Guile 2.2. Until then!