Good evening, gentle hackfolk!
Today I'd like to wrap up my three-part series of articles on what's new in Guile 2.2's compiler and runtime. I talked about the virtual machine a couple months ago, and the compiler internals just last Sunday. Today's article is about the object file format.
Sounds boring, right? Well, probably for most humans. But hackers, Guile compiles to ELF. Pretty rad, amirite? I thought so too. Read on, nerdy readers, read on!
object files
So let's consider the problem: Guile compiles to bytecode for a custom virtual machine. In the future we want to do native compilation. In both cases we'll need to write bytes out to disk in some format, and be able to load that code back into Guile. What should be the format for those bytes? For our purposes, a good object file format has a number of characteristics:
Above all else, it should be very cheap to load a compiled file.
It should be possible to statically allocate constants in the file. For example, a bytevector literal in source code can be emitted directly into the object file.
The compiled file should enable maximum code and data sharing between different processes.
The compiled file should contain debugging information, such as line numbers, but that information should be separated from the code itself. It should be possible to strip debugging information if space is tight.
These characteristics are not specific to Scheme. So why not just steal from the C and C++ people? They use the flexible ELF object file format, and so does Guile.
Note that although Guile uses ELF on all platforms, we do not use platform support for ELF. Guile implements its own linker and loader. The advantage of using ELF is not sharing code, but sharing ideas. ELF is simply a well-designed object file format.
An ELF file has two meta-tables describing its contents. The first meta-table is for the loader, and is called the program table or sometimes the segment table. The program table divides the file into big chunks that should be treated differently by the loader. Mostly the difference between these segments is their permissions.
Typically all segments of an ELF file are marked as read-only, except that part that represents modifiable static data or static data that needs load-time initialization. Loading an ELF file is as simple as mmapping the thing into memory with read-only permissions, then using the segment table to mark a small sub-region of the file as writable. This writable section is typically added to the root set of the garbage collector as well.
The other meta-table in an ELF file is the section table. Whereas the program table divides an ELF file into big chunks for the loader, the section table specifies small sections for use by introspective tools like debuggers or the like. One segment (program table entry) typically contains many sections. There may be sections outside of any segment, as well.
I know, this is a bit dry. So I made you a picture; or rather, a program that makes pictures. Here's an example of one of the pictures:
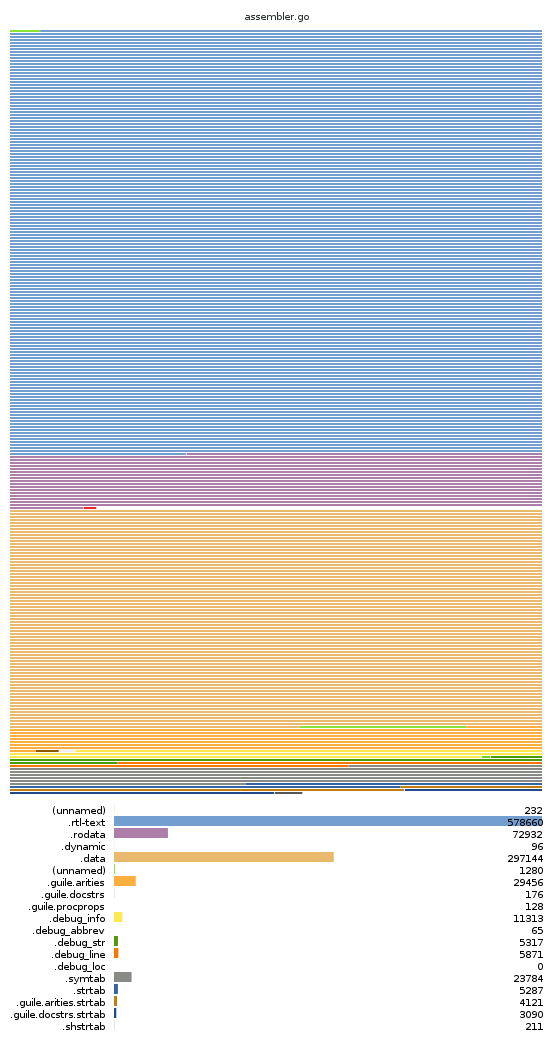
What we see here is a page map of assembler.go, a module in Guile's compiler. The upper part of the top shows each section in a different color, in the place they appear in the file. Each horizontal line is one four-kilobyte page.
As you can see, some pages contain multiple sections or parts of sections; that is the case for pages that have sections with the same permissions (read-only versus read-write), and which don't have special alignment requirements. About halfway down after the small red .dynamic section there is a gap, indicating that the next section, .data needs to start on a separate page -- in this case because it is writable.
This page map shows the sections of the ELF file. (There are only three segments; the first read-only part, a small "dynamic" segment holding the .dynamic section, used when the file is loaded; and the final read-write section. You can't see this from the visualization, but actually everything after .data is in no segment at all -- because it's not strictly necessary at run-time. That's the ELF convention.)
(Why is this file so big, you ask? It's a complicated answer. Part of it is because much of the assembler is itself a generated program; it uses Scheme procedural macros to define emit-foo procedures for each kind of instruction, based information extracted from the VM code (link). Guile doesn't do phasing, so these macros are residualized into the object file, and because of datum->syntax, macros have a lot of associated constant literals. That probably explains the huge size of .data, as syntax objects contain vectors and lists and symbols needing run-time relocation. I would have to check, but I think .rtl-text is big mostly because of a number of dynamic type checks in this particular module that the optimizer is (rightly) unable to elide. Alack. Surely both of these can be fixed eventually.)
But enough of problems. Did I mention that I made a program? And how! I think this may be the only blog post you have ever read that has a form in it, but that's how I am rolling today. Select an ELF file on your system, click submit, and you can have your very own page map. It works on any ELF file, not just Guile's files, so you can send your libc.so or whatever.
If you don't see a form above, your blog reader must have stripped it out. Click through to the blog post itself, or go visit the tool directly. And of course the program is written in Guile -- the file upload handling, the ELF parsing, and the pixel munging (using Cairo and a homebrew charting library).
Anyway, here's another example, this time of a small file:
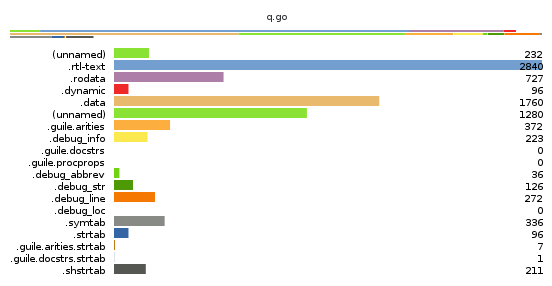
Here we see that this file has the same sections as our earlier bloated example, only they are smaller.
Allow me to point out some details.
Firstly, the .rtl-text section holds the bytecode. Usually this would be called .text, but I didn't want to mess with people's expectations, and the new VM used to be called the "RTL" VM. (No longer, that was a silly name.)
The .data section holds data that needs initialization, or which may be modified at runtime. .rodata holds statically allocated data that needs no run-time initialization, and which therefore can be shared between processes. The initializations themselves, like relocations, are compiled to a procedure in the .rtl-text section, linked to from the dynamic section.
And that's all the sections! Except for the introspection and debugging-related sections, that is. These sections are used by the Guile runtime to be able to answer questions like "what is the name of this function?" or "what is the source position corresponding to bytecode position X?" or "what is the documentation string for this function?" or, well, I think you get the point. None of this is usually needed at runtime, and because it is all allocated at the end of the file, that means that usually none of it is ever paged into memory.
Note that for some of this metadata we use the standard DWARF format. I think we are one of the few dynamic language runtimes that does this nifty thing.
Also, all read-only data in these ELF files is ripe for sharing between processes, paging out to disk if under memory pressure, etc. For example, if I look on the smaps file for one of the two web processes running on this server, I see:
/opt/guile-2.2/lib/guile/2.2/ccache/web/server/http.go Size: 132 kB Rss: 124 kB Pss: 62 kB
meaning that for this particular file, almost all of it is not only shareable but being shared. Good times.
Finally, all of this has a positive impact on start-up time. While I can get Guile 2.0 to start up in 11 milliseconds, with Guile 2.2 I am down to 8 milliseconds. Likewise guile -c '(sleep 100)' in Guile 2.0 uses 3144 kB of private dirty memory, compared to 1852 kB with Guile 2.2. There's still improvements to be made, but things are going well.
Well, again I find myself rambling. Check out the little ELF mapper tool I have above and let me know of any curious results. Do send your questions as well; though I've been derelict at responding, who knows, new year, new leaf right? Until next time, happy hacking.