multi-value webassembly in firefox: a binary interface
Hey hey hey! Hope everyone is staying safe at home in these weird times. Today I have a final dispatch on the implementation of the multi-value feature for WebAssembly in Firefox. Last week I wrote about multi-value in blocks; this week I cover function calls.
on the boundaries between things
In my article on Firefox's baseline compiler, I mentioned that all WebAssembly engines in web browsers treat the function as the unit of compilation. This facilitates streaming, parallel compilation of WebAssembly modules, by farming out compilation of individual functions to worker threads. It also allows for easy tier-up from quick-and-dirty code generated by the low-latency baseline compiler to the faster code produced by the optimizing compiler.
There are some interesting Conway's Law implications of this choice. One is that division of compilation tasks becomes an opportunity for division of human labor; there is a whole team working on the experimental Cranelift compiler that could replace the optimizing tier, and in my hackings on Firefox I have had minimal interaction with them. To my detriment, of course; they are fine people doing interesting things. But the code boundary means that we don't need to communicate as we work on different parts of the same system.
Boundaries are where places touch, and sometimes for fluid crossing we have to consider boundaries as places in their own right. Functions compiled with the baseline compiler, with Ion (the production optimizing compiler), and with Cranelift (the experimental optimizing compiler) are all able to call each other because they actively maintain a common boundary, a binary interface (ABI). (Incidentally the A originally stands for "application", essentially reflecting division of labor between groups of people making different components of a software system; Conway's Law again.) Let's look closer at this boundary-place, with an eye to how it changes with multi-value.
what's in an ABI?
Among other things, an ABI specifies a calling convention: which arguments go in registers, which on the stack, how the stack values are represented, how results are returned to the callers, which registers are preserved over calls, and so on. Intra-WebAssembly calls are a closed world, so we can design a custom ABI if we like; that's what V8 does. Sometimes WebAssembly may call functions from the run-time, though, and so it may be useful to be closer to the C++ ABI on that platform (the "native" ABI); that's what Firefox does. (Incidentally here I think Firefox is probably leaving a bit of performance on the table on Windows by using the inefficient native ABI that only allows four register parameters. I haven't measured though so perhaps it doesn't matter.) Using something closer to the native ABI makes debugging easier as well, as native debugger tools can apply more easily.
One thing that most native ABIs have in common is that they are really only optimized for a single result. This reflects their heritage as artifacts from a world built with C and C++ compilers, where there isn't a concept of a function with more than one result. If multiple results are required, they are represented instead as arguments, typically as pointers to memory somewhere. Consider the AMD64 SysV ABI, used on Unix-derived systems, which carefully specifies how to pass arbitrary numbers of arbitrary-sized data structures to a function (§3.2.3), while only specifying what to do for a single return value. If the return value is too big for registers, the ABI specifies that a pointer to result memory be passed as an argument instead.
So in a multi-result WebAssembly world, what are we to do? How should a function return multiple results to its caller? Let's assume that there are some finite number of general-purpose and floating-point registers devoted to return values, and that if the return values will fit into those registers, then that's where they go. The problem is then to determine which results will go there, and if there are remaining results that don't fit, then we have to put them in memory. The ABI should indicate how to address that memory.
When looking into a design, I considered three possibilities.
first thought: stack results precede stack arguments
When a function needs some of its arguments passed on the stack, it doesn't receive a pointer to those arguments; rather, the arguments are placed at a well-known offset to the stack pointer.
We could do the same thing with stack results, either reserving space deeper on the stack than stack arguments, or closer to the stack pointer. With the advent of tail calls, it would make more sense to place them deeper on the stack. Like this:
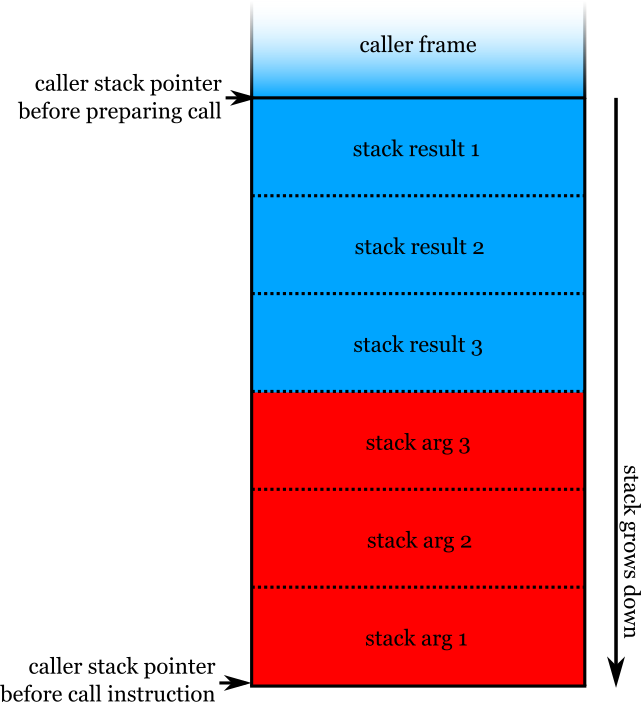
The diagram above shows the ordering of stack arguments as implemented by Firefox's WebAssembly compilers: later arguments are deeper (farther from the stack pointer). It's an arbitrary choice that happens to match up with what the native ABIs do, as it was easier to re-use bits of the already-existing optimizing compiler that way. (Native ABIs use this stack argument ordering because of sloppiness in a version of C from before I was born. If you were starting over from scratch, probably you wouldn't do things this way.)
Stack result order does matter to the baseline compiler, though. It's easier if the stack results are placed in the same order in which they would be pushed on the virtual stack, so that when the function completes, the results can just be memmove'd down into place (if needed). The same concern dictates another aspect of our ABI: unlike calls, registers are allocated to the last results rather than the first results. This is to make it easy to preserve stack invariant (1) from the previous article.
At first I thought this was the obvious option, but I ran into problems. It turns out that stack arguments are fundamentally unlike stack results in some important ways.
While a stack argument is logically consumed by a call, a stack result starts life with a call. As such, if you reserve space for stack results just by decrementing the stack pointer before a call, probably you will need to load the results eagerly into registers thereafter or shuffle them into other positions to be able to free the allocated stack space.
Eager shuffling is busy-work that should be avoided if possible. It's hard to avoid in the baseline compiler. For example, a call to a function with 10 arguments will consume 10 values from the temporary stack; any results will be pushed on after removing argument values from the stack. If there any stack results, it's almost impossible to avoid a post-call memmove, to move stack results to where they should be before the 10 argument values were pushed on (and probably spilled). So the baseline compiler case is not optimal.
However, things get gnarlier with the Ion optimizing compiler. Like many other optimizing compilers, Ion is designed to compute the necessary stack frame size ahead of time, and to never move the stack pointer during an activation. The only exception is for pushing on any needed stack arguments for nested calls (which are popped directly after the nested call). So in that case, assuming there are a number of multi-value calls in a stack frame, we'll be shuffling in the optimizing compiler as well. Not great.
Besides the need to shuffle, stack arguments and stack results differ as regards ownership and garbage collection. A callee "owns" the memory for its stack arguments; it is responsible for them. The caller can't assume anything about the contents of that memory after a call, especially if the WebAssembly implementation supports tail calls (a whole 'nother blog post, that). If the values being passed are just bits, that's one thing, but with the reference types proposal, some result values may be managed by the garbage collector. The callee is responsible for making stack arguments visible to the garbage collector; the caller is responsible for the results. The caller will need to emit metadata to allow the garbage collector to see stack result references. For this reason, a stack result actually starts life just before a call, because it can become initialized at any point and thus needs to be traced during the entire callee activation. Not all callers can easily add garbage collection roots for writable stack slots, so the need to place stack results in a fixed position complicates calling multi-value WebAssembly functions in some cases (e.g. from C++).
second thought: pointers to individual stack results
Surely there are more well-trodden solutions to the multiple-result problem. If we encoded a multi-value return in C, how would we do it? Consider a function in C that has three 64-bit integer results. The idiomatic way to encode it would be to have one of the results be the return value of the function, and the two others to be passed "by reference":
int64_t foo(int64_t* a, int64_t* b) {
*a = 1;
*b = 2;
return 3;
}
void call_foo(void) {
int64 a, b, c;
c = foo(&a, &b);
}
This program shows us a possibility for encoding WebAssembly's multiple return values: pass an additional argument for each stack result, pointing to the location to which to write the stack result. Like this:
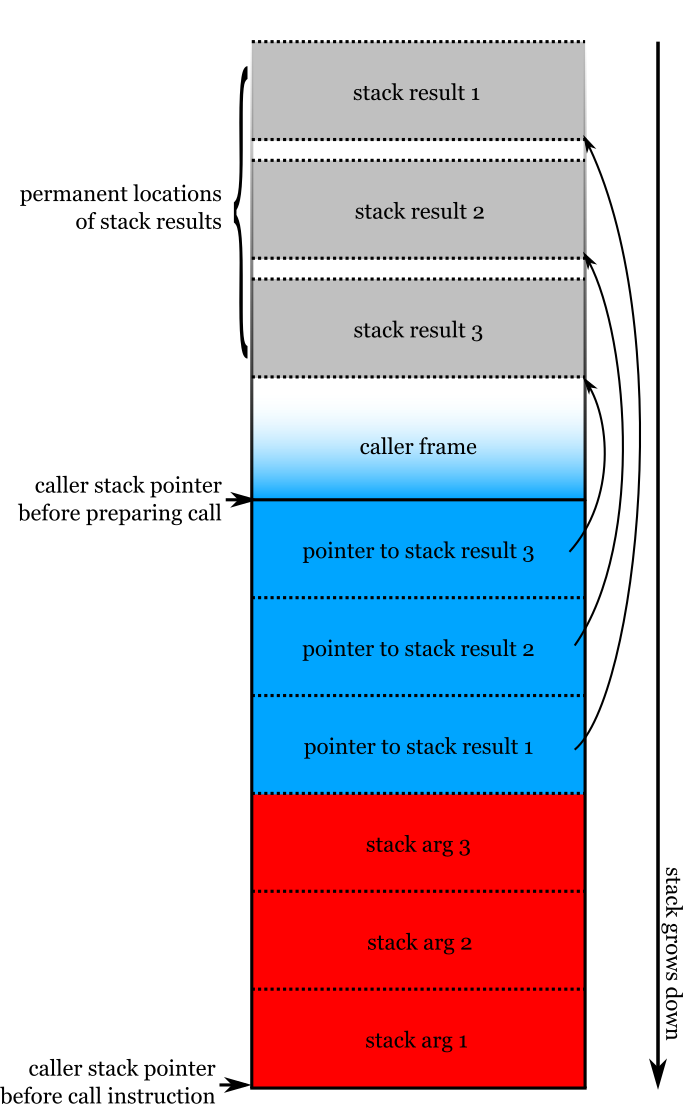
The result pointers are normal arguments, subject to normal argument allocation. In the above example, given that there are already stack arguments, they will probably be passed on the stack, but in many cases the stack result pointers may be passed in registers.
The result locations themselves don't even need to be on the stack, though they certainly will be in intra-WebAssembly calls. However the ability to write to any memory is a useful form of flexibility when e.g. calling into WebAssembly from C++.
The advantage of this approach is that we eliminate post-call shuffles, at least in optimizing compilers. But, having to make an argument for each stack result, each of which might itself become a stack argument, seems a bit offensive. I thought we might be able to do a little better.
third thought: stack result area, passed as pointer
Given that stack results are going to be written to memory, it doesn't really matter where they will be written, from the perspective of the optimizing compiler at least. What if we allocated them all in a block and just passed one pointer to the block? Like this:

Here there's just one additional argument, no matter how many stack results. While we're at it, we can specify that the layout of the stack arguments should be the same as how they would be written to the baseline stack, to make the baseline compiler's job easier.
As I started implementation with the baseline compiler, I chose this third approach, essentially because I was already allocating space for the results in a block in this way by bumping the stack pointer.
When I got to the optimizing compiler, however, it was quite difficult to convince Ion to allocate an area on the stack of the right shape.
Looking back on it now, I am not sure that I made the right choice. The thing is, the IonMonkey compiler started life as an optimizing compiler for JavaScript. It can represent unboxed values, which is how it came to be used as a compiler for asm.js and later WebAssembly, and it does a good job on them. However it has never had to represent aggregate data structures like a C++ class, so it didn't have support for spilling arbitrary-sized data to the stack. It took a while staring at the register allocator to convince it to allocate arbitrary-sized stack regions, and then to allocate component scalar values out of those regions. If I had just asked the register allocator to give me one appropriate-sized stack slot for each scalar, and hacked out the ability to pass separate pointers to the stack slots to WebAssembly calls with stack results, then I would have had an easier time of it, and perhaps stack slot allocation could be more dense because multiple results wouldn't need to be allocated contiguously.
As it is, I did manage to hack it in, and I think in a way that doesn't regress. I added a layer over an argument type vector that adds a synthetic stack results pointer argument, if the function returns stack results; iterating over this type with ABIArgIter will allocate a stack result area pointer, either as a register argument or a stack argument. In the optimizing compiler, I added add a kind of value allocation coresponding to a variable-sized stack area, (using pointer tagging again!), and extended the register allocator to allocate LStackArea, and the component stack results. Interestingly, I had to add a kind of definition that starts life on the stack; previously all Ion results started life in registers and were only spilled if needed.
In the end, a function will capture the incoming stack result area argument, either as a normal SSA value (for Ion) or stored to a stack slot (baseline), and when returning will write stack results to that pointer as appropriate. Passing in a pointer as an argument did make it relatively easy to implement calls from WebAssembly to and from C++, getting the variable-shape result area to be known to the garbage collector for C++-to-WebAssembly calls was simple in the end but took me a while to figure out.
Finally I was a bit exhausted from multi-value work and ready to walk away from the "JS API", the bit that allows multi-value WebAssembly functions to be called from JavaScript (they return an array) or for a JavaScript function to return multiple values to WebAssembly (via an iterable) -- but then when I got to thinking about this blog post I preferred to implement the feature rather than document its lack. Avoidance-of-document-driven development: it's a thing!
towards deployment
As I said in the last article, the multi-value feature is about improved code generation and also making a more capable base for expressing further developments in the WebAssembly language.
As far as code generation goes, things are progressing but it is still early days. Thomas Lively has implemented support in LLVM for emitting return of C++ aggregates via multiple results, which is enabled via the -experimental-multivalue-abi cc1 flag. Thomas has also been implementing multi-value support in the binaryen WebAssembly toolchain component, used by the emscripten C++-to-WebAssembly toolchain. I think it will be a few months though before everything lands in a way that end users can take advantage of.
On the specification side, the multi-value feature is now at phase 4 since January, which basically means things are all done there.
Implementation-wise, V8 has had experimental support since 2017 or so, and the feature was staged last fall, although V8 doesn't yet support multi-value in their baseline compiler. WebKit also landed support last fall.
Unlike V8 and SpiderMonkey, JavaScriptCore (the JS and wasm engine in WebKit) actually implements a WebAssembly interpreter as their solution to the one-pass streaming compilation problem. Then on the compiler side, there are two tiers that both operate on basic block graphs (OMG and BBQ; I just puked a little in my mouth typing that). This strategy makes the compiler implementation quite straightforward. It's also an interesting design point because JavaScriptCore's garbage collector scans the stack conservatively; there's no need for the compiler to do bookkeeping on the GC's behalf, which I'm sure was a relief to the hacker. Anyway, multi-value in WebKit is done too.
The new thing of course is that finally, in Firefox, the feature is now fully implemented (woo) and enabled by default on Nightly builds (woo!). I did that! It took me a while! Perhaps too long? Anyway it's done. Thanks again to Bloomberg for supporting this work; large ups to y'all for helping the web move forward.
See you next time with a more general article rounding up compile-time benchmarks on a variety of WebAssembly implementations. Until then, happy hacking!
2 responses
Comments are closed.
very cool! Thank you for sharing!
Thanks for the write up on your recent WebAssembly work (this post and your others). Perhaps there will be learnings you will bring back to Guile! :)