guile lab notebook: on the move!
Hey, a quick update, then a little story. The big news is that I got Guile wired to a moving garbage collector!
Specifically, this is the mostly-moving collector with conservative stack scanning. Most collections will be marked in place. When the collector wants to compact, it will scan ambiguous roots in the beginning of the collection cycle, marking objects referenced by such roots in place. Then the collector will select some blocks for evacuation, and when visiting an object in those blocks, it will try to copy the object to one of the evacuation target blocks that are held in reserve. If the collector runs out of space in the evacuation reserve, it falls back to marking in place.
Given that the collector has to cope with failed evacuations, it is easy to give the it the ability to pin any object in place. This proved useful when making the needed modifications to Guile: for example, when we copy a stack slice containing ambiguous references to a heap-allocated continuation, we eagerly traverse that stack to pin the referents of those ambiguous edges. Also, whenever the address of an object is taken and exposed to Scheme, we pin that object. This happens frequently for identity hashes (hashq).
Anyway, the bulk of the work here was a pile of refactors to Guile to allow a centralized scm_trace_object function to be written, exposing some object representation details to the internal object-tracing function definition while not exposing them to the user in the form of API or ABI.
bugs
I found quite a few bugs. Not many of them were in Whippet, but some were, and a few are still there; Guile exercises a GC more than my test workbench is able to. Today I’d like to write about a funny one that I haven’t fixed yet.
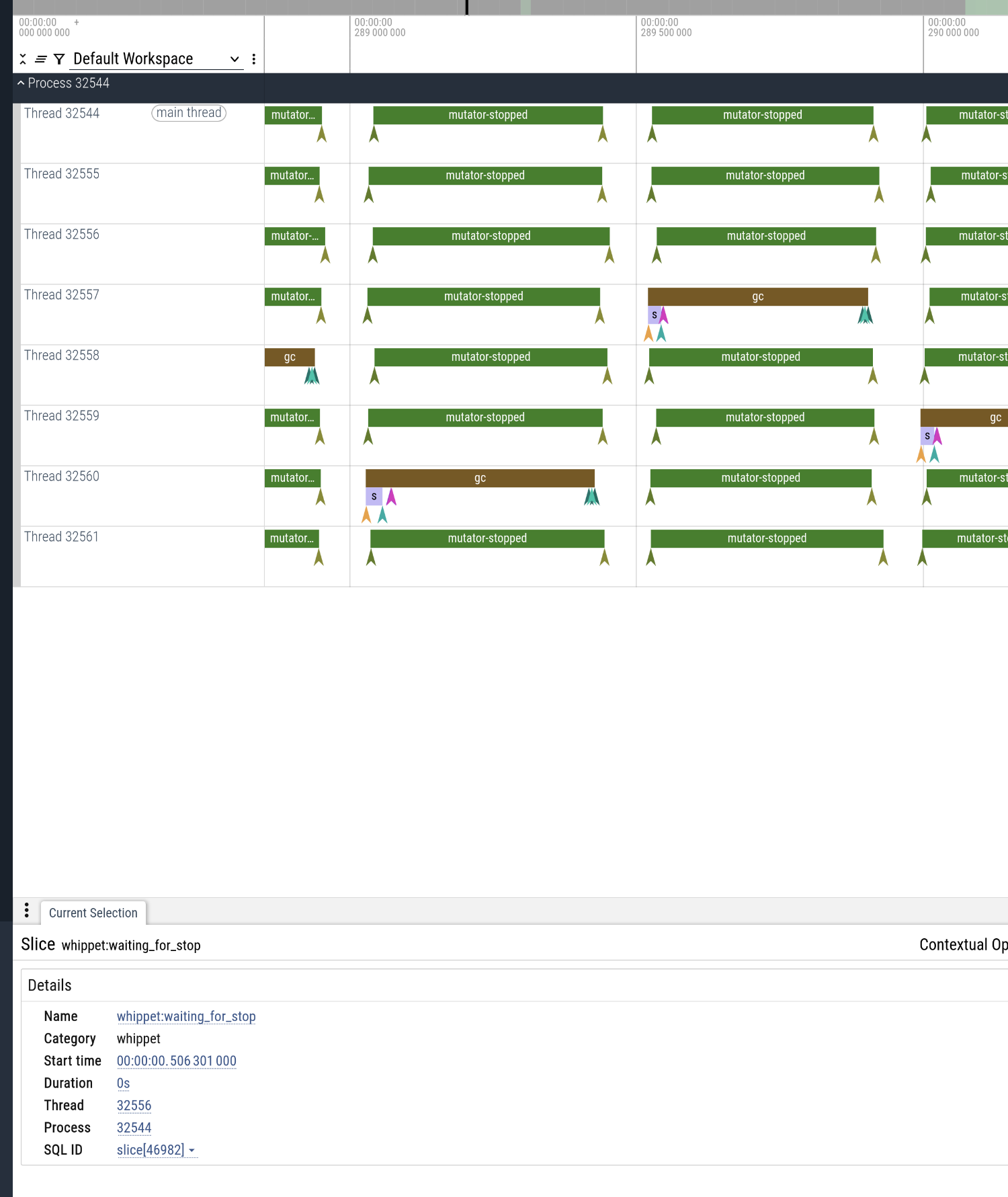
So, small objects in this garbage collector are managed by a Nofl space. During a collection, each pointer-containing reachable object is traced by a global user-supplied tracing procedure. That tracing procedure should call a collector-supplied inline function on each of the object’s fields. Obviously the procedure needs a way to distinguish between different kinds of objects, to trace them appropriately; in Guile, we use an the low bits of the initial word of heap objects for this purpose.
Object marks are stored in a side table in associated 4-MB aligned slabs, with one mark byte per granule (16 bytes). 4 MB is 0x400000, so for an object at address A, its slab base is at A & ~0x3fffff, and the mark byte is offset by (A & 0x3fffff) >> 4. When the tracer sees an edge into a block scheduled for evacuation, it first checks the mark byte to see if it’s already marked in place; in that case there’s nothing to do. Otherwise it will try to evacuate the object, which proceeds as follows...
But before you read, consider that there are a number of threads which all try to make progress on the worklist of outstanding objects needing tracing (the grey objects). The mutator threads are paused; though we will probably add concurrent tracing at some point, we are unlikely to implement concurrent evacuation. But it could be that two GC threads try to process two different edges to the same evacuatable object at the same time, and we need to do so correctly!
With that caveat out of the way, the implementation is here. The user has to supply an annoyingly-large state machine to manage the storage for the forwarding word; Guile’s is here. Basically, a thread will try to claim the object by swapping in a busy value (-1) for the initial word. If that worked, it will allocate space for the object. If that failed, it first marks the object in place, then restores the first word. Otherwise it installs a forwarding pointer in the first word of the object’s old location, which has a specific tag in its low 3 bits allowing forwarded objects to be distinguished from other kinds of object.
I don’t know how to prove this kind of operation correct, and probably I should learn how to do so. I think it’s right, though, in the sense that either the object gets marked in place or evacuated, all edges get updated to the tospace locations, and the thread that shades the object grey (and no other thread) will enqueue the object for further tracing (via its new location if it was evacuated).
But there is an invisible bug, and one that is the reason for me writing these words :) Whichever thread manages to shade the object from white to grey will enqueue it on its grey worklist. Let’s say the object is on an block to be evacuated, but evacuation fails, and the object gets marked in place. But concurrently, another thread goes to do the same; it turns out there is a timeline in which the thread A has marked the object, published it to a worklist for tracing, but thread B has briefly swapped out the object’s the first word with the busy value before realizing the object was marked. The object might then be traced with its initial word stompled, which is totally invalid.
What’s the fix? I do not know. Probably I need to manage the state machine within the side array of mark bytes, and not split between the two places (mark byte and in-object). Anyway, I thought that readers of this web log might enjoy a look in the window of this clown car.
next?
The obvious question is, how does it perform? Basically I don’t know yet; I haven’t done enough testing, and some of the heuristics need tweaking. As it is, it appears to be a net improvement over the non-moving configuration and a marginal improvement over BDW, but which currently has more variance. I am deliberately imprecise here because I have been more focused on correctness than performance; measuring properly takes time, and as you can see from the story above, there are still a couple correctness issues. I will be sure to let folks know when I have something. Until then, happy hacking!

{kind=link}